Den genetiske koden: uoverstigelig problem for ikke-intelligent opphav
Oversatt herfra. {Kursiv og/eller understreking - tilsatt av oversetter.}
 Koder er produkt av et sinn. En tenkende enhet utenfor cellen må være ansvarlig for den doble delen av DNA og protein, som bruker forskjellige språk og likevel kan kommunisere med hverandre. Man ville aldri våge å insistere på at tilfeldig orden kunne skape morse-koden eller metoden for blindeskrift (Braille). Det ville være helt irrasjonelt. DNA-basesekvensering kan ikke forklares tilfeldig, eller med fysisk nødvendighet, mer enn informasjonen i en avis-overskrift kan forklares med henvisning til de kjemiske egenskapene til trykksverte. Konvensjonene til den genetiske koden som bestemmer tildelingen mellom nukleotid-tripletter og aminosyrer under oversettelse, kan heller ikke forklares på denne måten. Den genetiske koden fungerer som en grammatisk konvensjon for et menneskelig språk. Egenskapene/formen til byggesteiner/blokker bestemmer ikke arrangementet i konstruksjonen av et hus eller en vegg. Tilsvarende bestemmer egenskapene til biologiske byggesteiner ikke arrangementet av monomerer i funksjonelle, informasjonsbærende DNA- og RNA-polypeptider, og heller ikke proteinstrenger.
Koder er produkt av et sinn. En tenkende enhet utenfor cellen må være ansvarlig for den doble delen av DNA og protein, som bruker forskjellige språk og likevel kan kommunisere med hverandre. Man ville aldri våge å insistere på at tilfeldig orden kunne skape morse-koden eller metoden for blindeskrift (Braille). Det ville være helt irrasjonelt. DNA-basesekvensering kan ikke forklares tilfeldig, eller med fysisk nødvendighet, mer enn informasjonen i en avis-overskrift kan forklares med henvisning til de kjemiske egenskapene til trykksverte. Konvensjonene til den genetiske koden som bestemmer tildelingen mellom nukleotid-tripletter og aminosyrer under oversettelse, kan heller ikke forklares på denne måten. Den genetiske koden fungerer som en grammatisk konvensjon for et menneskelig språk. Egenskapene/formen til byggesteiner/blokker bestemmer ikke arrangementet i konstruksjonen av et hus eller en vegg. Tilsvarende bestemmer egenskapene til biologiske byggesteiner ikke arrangementet av monomerer i funksjonelle, informasjonsbærende DNA- og RNA-polypeptider, og heller ikke proteinstrenger.
Cellen bruker ofte en funksjonell logikk som speiler vår egen, men overgår den i eleganse, i utførelsen. "Det er som vi ser på 8.0 eller 9.0 versjoner av designstrategier, som vi nettopp har begynt å implementere. Når jeg ser hvordan cellen behandler informasjon", sa han,"gir det meg en uhyggelig følelse av at noen andre fant ut av dette før vi kom hit."
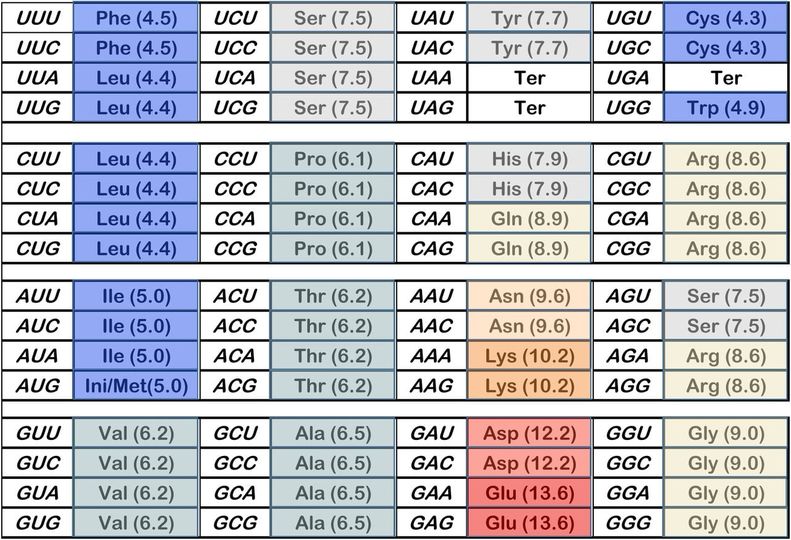
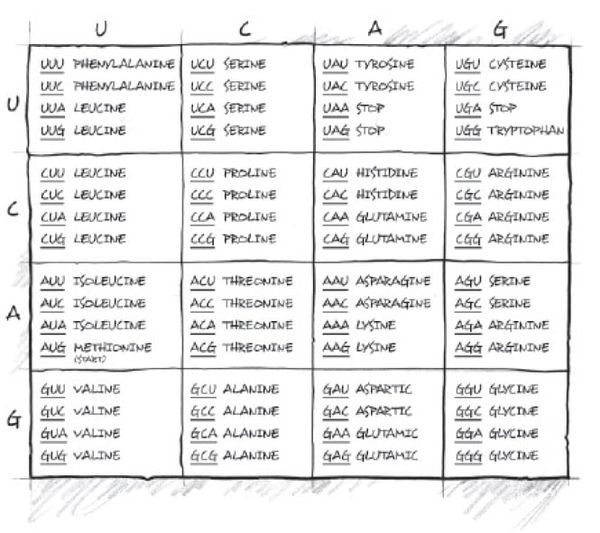
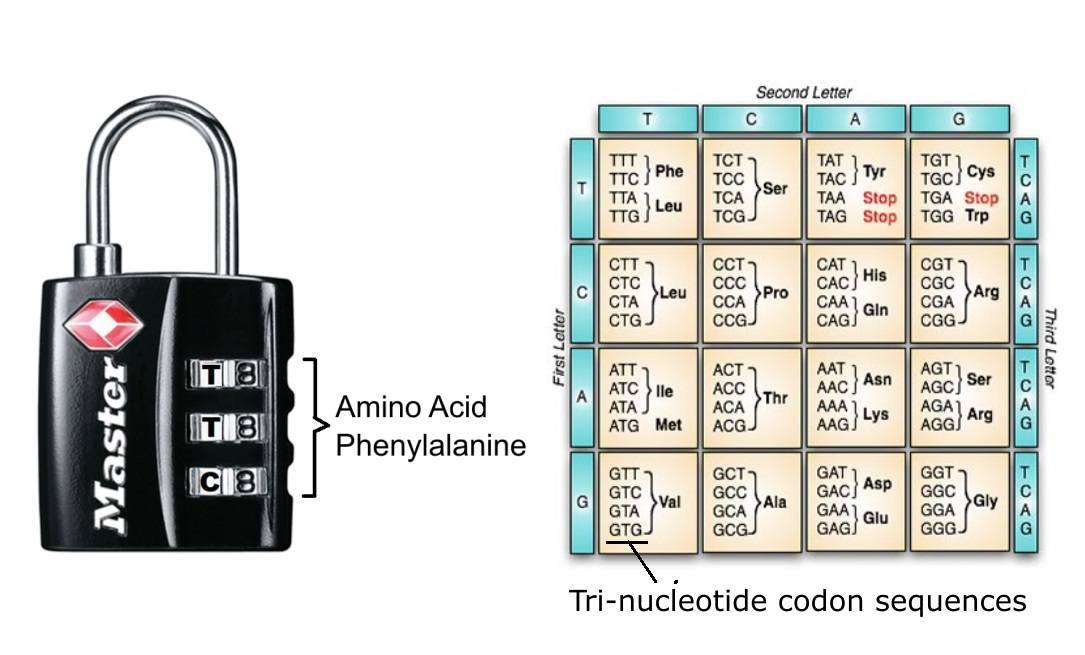
Standard genetisk kode som viser de spesifikke aminosyrene som DNA-basetripletter, spesifiseres etter at de er transkribert og oversatt under genuttrykk.
Den genetiske koden tildeler lignende kodoner til aminosyrer med lignende polare krav. Ved en tilfeldighet, eller design? !!
På figuren er hver triplett farget, med hydrofobe polare krav -blå, mellomliggende -grå og veldig polære sidekjeder -røde. StandardGenetisk Kode SGK er overordentlig høyt ordnet med hensyn til polarkravet, med store sammenhengende domener for hydrofobe, mellomliggende og polære aminosyrer (Polare aminosyrer er de med sidekjeder som foretrekker å ligge i en vannlig miljø.) Standard Genetisk Kode (SGK) sin inndeling i noen få sammenhengende regioner, er spesielt slående -lenke.
DNA-basesekvensering kan ikke forklares tilfeldig, og heller ikke ved fysisk nødvendighet, mer enn informasjonen i en avisoverskrift kan forklares med henvisning til de kjemiske egenskapene til trykksverte. Konvensjonene ved den genetiske koden som bestemmer tilordningene mellom nukleotidtripletter og aminosyrer under oversettelse kan heller ikke forklares på denne måten.
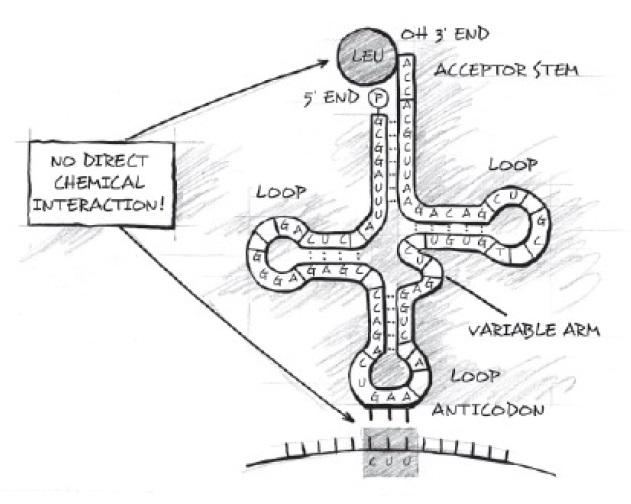
Den genetiske koden er for den genetiske informasjonen på en DNA-streng, lik Morse-koden for en spesifikk melding, mottatt av en telegrafoperatør. Molekylærbiologer har ikke funnet noen signifikant kjemisk  interaksjon.
interaksjon.
1. Tildelingen av et ord for å representere noe, som ordet 'stol' på et objekt å sette seg ned på, er alltid av mental opprinnelse.
2. Oversettelsen av et ord på ett språk, til et annet språk, er alltid av mental opprinnelse. For eksempel kan tildelingen av ordet stol, på engelsk (chair), til xizi, på kinesisk, bare gjøres av intelligens bygd på felles forståelse av mening.
3. I biologi er den genetiske koden tildelingen og konvensjonen (en kryptering) av 64 triplettkodoner tilsvarende 20 aminosyrer. Det fungerer som en beskrankning på høyere nivå, som er forskjellig fra fysiske og kjemiske lover, omtrent som en grammatisk konvensjon på et menneskelig språk.
4. Siden vi bare kjenner til intelligens for å kunne klare dette, forklares denne oppgaven best av bevisst, vilkårlig handling fra en ikke-menneskelig intelligent agent.
1. Opprinnelsen til den genetiske krypteringen
1. Triplettkodoner må tilordnes aminosyrer for å etablere en genetisk kryptering. Nukleinsyrebaser og aminosyrer gjenkjenner ikke hverandre direkte, men må håndteres via kjemiske mellomledd (tRNA og aminoacyl tRNA-syntetase), det er ingen åpenbar grunn til at bestemte tripletter bør gå med bestemte aminosyrer.
2. Andre oversettelsesoppdrag er tenkelige, men uansett hvilken kryptering som er etablert, må de riktige aminosyrene tildeles, for å tillate polypeptidkjeder som foldes, til aktive funksjonelle proteiner. Funksjonelle aminosyrekjeder i sekvensrom er sjeldne. Det er to muligheter for å forklare den korrekte tildelingen av kodonene til de rette aminosyrene. Sjanse og design. Naturlig seleksjon er ikke et alternativ, siden DNA-replikering ikke er satt opp før en selvrepliserende celle fungerer, men denne oppgaven måtte etableres på forhånd.
 3. Hvis det var en heldig ulykke som skjedde ved en tilfeldighet, ville flaks truffet jackpoten gjennom prøving og feiling blant 1,5 * (10^84) mulige genetiske kodetabeller. Det er antall atomer i hele universet. Det setter enhver reell mulighet for sjanse til å utføre bragden, ut av spill. Det tilsvarer å bruke Borels lov, i umulighetsområdet. Naturlig utvalg måtte evaluere omtrent 10^55 koder per sekund for å finne den som er universell. Enkelt sagt mangler det kjemiske lotteriet den tiden som er nødvendig, for å finne den universelle genetiske koden.
3. Hvis det var en heldig ulykke som skjedde ved en tilfeldighet, ville flaks truffet jackpoten gjennom prøving og feiling blant 1,5 * (10^84) mulige genetiske kodetabeller. Det er antall atomer i hele universet. Det setter enhver reell mulighet for sjanse til å utføre bragden, ut av spill. Det tilsvarer å bruke Borels lov, i umulighetsområdet. Naturlig utvalg måtte evaluere omtrent 10^55 koder per sekund for å finne den som er universell. Enkelt sagt mangler det kjemiske lotteriet den tiden som er nødvendig, for å finne den universelle genetiske koden.
4. Vi har ikke engang vurdert at det også er over 500 mulige aminosyrer som må ordnes for å få bare 20, og velge alle L-amino- og R-sukkerbaser ......
5. Vi vet at bevisstheter/sinn oppfinner språk, koder, oversettelsessystemer og kompleks spesifisert informasjon hele tiden.
6. Sagt det med andre ord: Oppgaven kan sammenlignes med å finne opp to språk, to alfabeter og et oversettelsessystem, og informasjonsinnholdet i en bok (for eksempel Hamlet) blir opprettet og skrevet på engelsk, og oversatt til kinesisk, gjennom oppfinnelse og anvendelse av et ekstremt sofistikert maskinvaresystem.
7. Den genetiske koden og dens oversettelsessystem forklares best gjennom handling fra en intelligent designer.
Den genetiske koden ble mest sannsynlig implementert av intelligens.
1. I kommunikasjon og informasjonsbehandling er kode et regelsett for å konvertere informasjon - for eksempel å tildele betydningen av en bokstav, et ord til en annen form (som et annet ord, en bokstav osv.)
2. I oversettelse tildeles 64 genetiske kodoner til 20 aminosyrer. Det refererer til tildelingen av kodonene til aminosyrene, og er dermed hjørnesteinsmalen som ligger til grunn for oversettelsesprosessen.
3. Tilordning innebærer å betegne, diktere, tilskrive, korrespondere, korrelere, spesifisere, representere, bestemme, kartlegge, permutere.
4. Den universelle genetiske triplett-nukleotidkoden kan være resultatet av enten a) et tilfeldig utvalg gjennom evolusjon, eller b) resultatet av intelligent implementering.
5. Vi vet av erfaring at det å utføre verditildeling og kodifisering alltid er en prosess av intelligens med et tiltenkt resultat. Ikke-intelligens, aka materie, molekyler, nukleotider, etc. har aldri vist seg å være i stand til å generere koder, og har verken hensikt eller fjerne mål med framsyn, i den hensikt å produsere spesifikke resultater.
6. Derfor er den genetiske koden resultatet av et intelligent oppsett.
"Vår erfaringsbaserte kunnskap om informasjonsflyt bekrefter at systemer med store mengder spesifisert kompleksitet (spesielt koder og språk) alltid kommer fra en intelligent kilde - fra et sinn eller en personlig agent."
- Stephen C. Meyer, "Opprinnelsen til biologisk informasjon og de høyere taksonomiske kategoriene," Proceedings of the Biological Society of Washington, 117 (2): 213-239 (2004).
"Som den banebrytende informasjonsteoretikeren Henry Quastler en gang bemerket, er informasjonskaping ofte knyttet til bevisst aktivitet." Og selvfølgelig hadde han rett. Hver gang vi finner informasjon - enten det er innebygd i et radiosignal, skåret i et steinmonument, skrevet i en bok eller etset på en magnetisk disk - og vi sporer den tilbake til kilden, kommer vi alltid til en intelligent  kilde, ikke bare en materiell prosess.
kilde, ikke bare en materiell prosess.
Dermed gir oppdagelsen av funksjonell spesifisert, digitalt kodet informasjon langs DNA-tråden overbevisende positivt bevis på aktiviteten til en tidligere designende intelligens. Denne konklusjonen er ikke basert på det vi ikke vet. Den er basert på det vi vet fra vår ensartede erfaring om årsaks- og virkningsstrukturen i verden - spesifikt hva vi vet om hva som produserer og ikke har makten til å produsere, store mengder spesifisert informasjon. "
- Stephen Meyer
"Et kodesystem er alltid et resultat av en mental prosess (det krever en intelligent opprinnelse eller oppfinner). Det bør understrekes at materie som sådan ikke er i stand til å generere noen kode. Alle erfaringer indikerer at det er nødvendig å tenke å være frivillig å utøve sin egen frie vilje, erkjennelse og kreativitet. ... det er ingen kjent naturlov og ingen kjent rekkefølge av hendelser som kan føre til at informasjon stammer fra seg selv i materie."
Werner Gitt 1997 In The Beginning Was Information s. 64-67, 79, 107.
(Den pensjonerte Dr Gitt var direktør og professor ved det tyske føderale instituttet for fysikk og teknologi (Physikalisch-Technische Bundesanstalt, Braunschweig), leder for Institutt for informasjonsteknologi.)
"På grunn av Shannon-kanalkapasiteten måtte det forrige (første) kodonalfabetet være minst like komplekst som det nåværende kodonalfabetet (DNA-kode), ellers ville det ha vært matematisk umulig å overføre informasjonen fra det enklere alfabetet til det nåværende alfabetet"
Donald E. Johnson, i - Bioinformatics: The Information in Life
"Den genetiske kodens feil-minimeringsegenskaper er langt mer dramatiske enn disse (én av en million) resultatene indikerer. Da forskerne beregnet feilminimeringskapasiteten til en million tilfeldig genererte genetiske koder, oppdaget de at feilminimeringsverdiene dannet en fordeling. Forskere estimerer eksistensen av 10^18 mulige genetiske koder som har samme type og grad av redundans som den universelle genetiske koden. Alle disse kodene faller innenfor distribusjonen av feilminimering. Dette betyr at 10^18 koder har få, om noen, en feilminimeringskapasitet som nærmer seg koden som finnes universelt i hele naturen."
Fazale Rana - Fra side 175; 'The Cell's Design'
Den genetiske koden kunne ikke være et produkt av evolusjon, siden den måtte være fullt operativ når livet startet (og altså DNA-replikering, som evolusjonen avhenger av). Det eneste alternativet til design, er at tilfeldige, ikke-styrte hendelser avstedkom det.
Bilde: Ingen direkte kjemisk interaksjon
Barbieri: Code Biology:
 "... det er ingen deterministisk kobling mellom kodoner og aminosyrer fordi ethvert kodon kan assosieres med hvilken som helst aminosyre. Dette betyr at reglene for den genetiske koden ikke stammer fra kjemisk nødvendighet, og i denne forstand er de vilkårlige." "... vi har eksperimentelle bevis for at den genetiske koden er en reell kode, en kode som er kompatibel med lovene i fysikk og kjemi, men som ikke er diktert av dem." -lenke.
"... det er ingen deterministisk kobling mellom kodoner og aminosyrer fordi ethvert kodon kan assosieres med hvilken som helst aminosyre. Dette betyr at reglene for den genetiske koden ikke stammer fra kjemisk nødvendighet, og i denne forstand er de vilkårlige." "... vi har eksperimentelle bevis for at den genetiske koden er en reell kode, en kode som er kompatibel med lovene i fysikk og kjemi, men som ikke er diktert av dem." -lenke.
[Kommentar til andre biologiske koder]: "I signaltransduksjon finner vi kort sagt alle viktige komponenter i en kode: (a) to uavhengige verdener av molekyler (første budbringere og andre budbringere), (b) et sett med adaptere som lager en kartlegging mellom dem, og (c) beviset på at kartleggingen er vilkårlig fordi reglene kan endres på mange forskjellige måter. "
Hvorfor skal eller vil molekyler fremme betegne, tildele, diktere, tilskrive, korrespondere, korrelere, spesifisere noe i det hele tatt? . Hvordan gir det mening? Dette er ikke et argument fra vantro. Proposisjonen trosser rimelige prinsipper og det kjente og begrensede, uspesifikke spekter av tilfeldigheter, fysisk nødvendighet, mutasjoner og naturlig utvalg. Det vi trenger er å gi en 'sannsynlig' redegjørelse for hvordan det i utgangspunktet ble til.
Det er i ethvert scenario fjernt å tro at ikke-ledede tilfeldige hendelser vil produsere et funksjonelt kodesystem og vilkårlige tildelinger av mening. Det er ganske enkelt å sette altfor mye lit til hva molekyler alene kan gjøre.
RNA, (hvis de uansett eksisterte prebiotisk), ville bare ligge og oppløse seg på kort tid. Hvis vi vurderer at den prebiotiske syntesen av RNA aldri har blitt demonstrert i laboratoriet, ville de ikke polymerisere. Leireksperimenter har mislyktes. Systemer, gitt energi og overlatt til seg selv, DEVOLVERER til å gi ubrukelig komplekse blandinger, 'asfalt'. Litteraturen rapporterer (så vidt vi vet) nøyaktig NULL BEKREFTEDE OBSERVASJONER der molekylkompleksisering spontant kom frem fra en pool av tilfeldige kjemikalier. Det er UMULIG for ethvert ikke-levende kjemisk system å unnslippe devolusjon, for å komme inn i en verden av de 'levende'.
Alberts: The Molecular Biology of the Cell et al, p367
Forholdet mellom en DNA-sekvens og sekvensen til det tilsvarende proteinet kalles den genetiske koden ... den genetiske koden blir dekryptert av et komplekst apparat som tolker nukleinsyresekvensen.
Gener VIII, av Lewin, p21-22
... konvertering av informasjonen i [messenger] RNA representerer en oversettelse av informasjonen til et annet språk som bruker ganske forskjellige symboler.
Det strukturelle grunnlaget for den genetiske koden: aminosyregjenkjenning av aminoacyl-tRNA-syntetaser
 Et av de mest dype åpne spørsmålene i biologien er hvordan den genetiske koden ble etablert. Fremveksten av dette selvhenvisende systemet utgjør et 'kylling-eller-egg'-dilemma, og dets opprinnelse er fortsatt sterkt diskutert -lenke.
Et av de mest dype åpne spørsmålene i biologien er hvordan den genetiske koden ble etablert. Fremveksten av dette selvhenvisende systemet utgjør et 'kylling-eller-egg'-dilemma, og dets opprinnelse er fortsatt sterkt diskutert -lenke.
Genomikk: Utvikling av den biologiske-koden (Lewin fortsetter):
Å forstå hvordan denne koden oppsto og hvordan den påvirker molekylærbiologien og evolusjonen i livet i dag, er utfordrende problemer, delvis fordi den er så godt bevart - uten observert variasjon er det vanskelig å dissekere de funksjonelle implikasjonene av forskjellige aspekter av et tegn.
Det er fristende å tenke at et system så sentralt i livet skal være elegant, men det er selvfølgelig ikke slik evolusjon fungerer; Den genetiske koden ble ikke designet av smarte forskere, men bygget opp gjennom en rekke tilfeldigheter. Den 'frosne ulykken', som den ble beskrevet av Crick, som til slutt dukket opp, er absolutt ikke tilfeldig, men er mer en ulykke enn en elegant plan, som førte til nye ideer om hvordan koden kan ha utviklet seg i en serie trinn fra enklere koder med færre aminosyrer. Så koden var ikke alltid slik, men når den ble etablert før den siste universelle felles forfaren til alt levende liv (LUCA), har den holdt seg under veldig kraftige selektive begrensninger som holdt koden frossen i nesten alle genomer som senere diversifiserte -lenke.
Grassos kommentar: En rekke tilfeldigheter !!! mer en mishmash enn en elegant plan !!! Sjansemessig (contingent) betyr tilfeldig, tilfeldig, tilfeldig, tilfeldig, sjanse. Så, med andre ord, flaks. En tilfeldig ulykke. Er det et rasjonelt forslag?
De genetiske kodonene er tildelt aminosyrer. Hvorfor skal eller ville molekyler fremme betegne, diktere, tilskrive, korrespondere, korrelere, spesifisere noe i det hele tatt? Hvordan gir det mening?
Den genetiske koden kunne ikke være et produkt av evolusjon, siden den måtte være fullt operativ når livet startet (og altså DNA-replikering, som evolusjonen avhenger av). Det eneste alternativet til design er at tilfeldige, ikke-styrte hendelser ga det sin opprinnelse.
Biologi-kode 2
"... det er ingen deterministisk kobling mellom kodoner og aminosyrer fordi ethvert kodon kan assosieres med hvilken som helst aminosyre. Dette betyr at reglene for den genetiske koden ikke stammer fra kjemisk nødvendighet, og i denne forstand er de vilkårlige." "... vi har eksperimentelle bevis for at den genetiske koden er en reell kode, en kode som er kompatibel med lovene i fysikk og kjemi, men som ikke er diktert av dem."
[Kommentar til andre biologiske koder]: "I signaltransduksjon finner vi kort sagt alle viktige komponenter i en kode: (a) to uavhengige verdener av molekyler (første budbringere og andre budbringere), (b) et sett med adaptere som lager en tilordning mellom dem, og (c) beviset på at kartleggingen er vilkårlig fordi reglene kan endres på mange forskjellige måter. "
RNA-er, (hvis de uansett eksisterte prebiotisk), ville bare ligge og oppløse seg i løpet av kort tid (en måned eller så). Hvis vi vurderer at den prebiotiske syntesen av RNA aldri har blitt demonstrert i laboratoriet, ville de ikke polymerisere seg. Simulerings-eksperimenter har mislyktes. Og selv om de ville binde seg i GC-rike konfigurasjoner til små peptider, ville de like gjerne ligge rundt og gå i oppløsning. Det er i ETHVERT scneario et drøyt stykke å tro at ikke-styrte hendelser vil produsere tilfeldige koder. Det er rett og slett å sette altfor mye tillit til hva molekyler alene kan gjøre.
Grassos kommentar: Uten stoppkodoner ville ikke oversettelsesmaskineriet vite hvor de skulle avslutte proteinsyntesen, og det kunne/ville aldri være funksjonelle proteiner og ikke noe liv på jorden. I det hele tatt.
Disse egenskapene kan gjøre slike endringer mer statistisk sannsynlige, mindre sannsynlige å være skadelige, eller begge deler. Imidlertid er de fleste ikke-kanoniske genetiske koder utledet fra DNA-sekvensen alene, eller noen ganger fra DNA-sekvenser og tilsvarende tRNAer.

Opprinnelse og utvikling av den genetiske koden: Den universelle gåten -2009 Feb Eugene V. Koonin:
Etter vår mening, til tross for omfattende og, i mange tilfeller forseggjorte forsøk på å modellere kodeoptimalisering, genial teoretisering i retning av koevolusjonsteorien, og betydelig eksperimentering, har det blitt gjort svært få endelige fremskritt. Når vi oppsummerer det nyeste innen studiet av kodeutviklingen, kan vi ikke unngå betydelig skepsis. Det ser ut til at det todelt fundamentale spørsmålet: "Hvorfor er den genetiske koden slik den er og hvordan ble den til?", Som ble spurt for over 50 år siden, ved begynnelsen av molekylærbiologien, kan forbli relevant selv i 50 år til. Vår trøst er at vi ikke kan tenke på et mer grunnleggende problem i biologien.
Mange av de samme kodonene omfordeles (sammenlignet med standardkoden) i uavhengige linjer (f.eks. er den hyppigste endringen omfordelingen av stoppkodonet UGA til tryptofan), denne konklusjonen innebærer at det burde være disposisjon mot visse endringer; Minst en av disse endringene ble rapportert å gi selektiv fordel.
Opprinnelsen til den genetiske koden er anerkjent for å være et stort hinder i livets opprinnelse, og jeg skal nevne bare ett eller to av hovedproblemene. Å kalle det en 'kode' kan være misvisende på grunn av at å knytte den til menneskelig oppfunnede koder som i sin kjerne vanligvis innebærer en slags forhåndsutviklet algoritme; mens den genetiske koden implementeres helt mekanisk - gjennom virkningen av biologiske makromolekyler. Dette understreker at, å ha oppstått naturlig - f.eks. gjennom tilfeldig mutasjon og naturlig seleksjon - intet fremsyn er tillatt: Alle komponentene ville ha måttet oppstått på en opportunistisk måte.
Avgjørende rolle for tRNA-aktiverende enzymer
For å prøve å forklare kilden til koden har forskjellige forskere søkt etter en slags kjemisk affinitet mellom aminosyrer og deres tilsvarende kodoner. Men denne tilnærmingen er misvisende: Først og fremst medieres koden av tRNAer som bærer antikodonet (i mRNA) i stedet for selve kodonet (i DNA). Så hvis koden var basert på tilhørighet mellom aminosyrer og anti-kodoner, innebærer det at prosessen med oversettelse via transkripsjon ikke kan ha oppstått som et andre trinn eller forbedring av et enklere direkte system - den komplekse totrinnsprosessen vil trenge å ha oppstått helt fra starten.
 For det andre har aminosyren ingen rolle i å identifisere tRNA eller kodon (Dette kan sees fra et eksperiment der aminosyren cystein var bundet til sitt passende tRNA på normal måte - ved hjelp av det aktuelle aktiverende enzymet, og så var det kjemisk modifisert til alanin. Når det endrede aminoacyl-tRNA ble brukt i et in vitro proteinsyntetiseringssystem (inkludert mRNA, ribosomer etc.), inneholdt det resulterende polypeptidet alanin (i stedet for vanlig cystein) tilsvarende hvor kodon UGU befant seg i mRNA. Dette viser tydelig at det er tRNA alene (uten rolle for aminosyren) med passende antikodon, som samsvarer med kodonet på mRNA.). Denne assosiasjonen er utført av et aktiverende enzym (aminoacyl-tRNA-syntetase) som fester hver aminosyre til sitt passende tRNA (som tydelig krever at dette enzymet identifiserer begge komponentene riktig) Det er 20 forskjellige aktiverende enzymer - en for hver type aminosyre.
For det andre har aminosyren ingen rolle i å identifisere tRNA eller kodon (Dette kan sees fra et eksperiment der aminosyren cystein var bundet til sitt passende tRNA på normal måte - ved hjelp av det aktuelle aktiverende enzymet, og så var det kjemisk modifisert til alanin. Når det endrede aminoacyl-tRNA ble brukt i et in vitro proteinsyntetiseringssystem (inkludert mRNA, ribosomer etc.), inneholdt det resulterende polypeptidet alanin (i stedet for vanlig cystein) tilsvarende hvor kodon UGU befant seg i mRNA. Dette viser tydelig at det er tRNA alene (uten rolle for aminosyren) med passende antikodon, som samsvarer med kodonet på mRNA.). Denne assosiasjonen er utført av et aktiverende enzym (aminoacyl-tRNA-syntetase) som fester hver aminosyre til sitt passende tRNA (som tydelig krever at dette enzymet identifiserer begge komponentene riktig) Det er 20 forskjellige aktiverende enzymer - en for hver type aminosyre.
Interessant nok har enden av tRNA som aminosyren fester seg til, den samme nukleotidsekvensen for alle aminosyrer - noe som utgjør en tredje årsak.
For det tredje: Interessen for den genetiske koden har en tendens til å fokusere på tRNAs rolle, men som bare antydet er det bare halvparten av implementeringen av koden. Like viktig som kodon-antikodon-sammenkoblingen (mellom mRNA og tRNA) er evnen til hvert aktiverende enzym til å bringe sammen en aminosyre med sitt passende tRNA. Det er tydelig at implementering av koden krever to sett med mellomliggende molekyler: tRNAene som samhandler med ribosomene og gjenkjenner riktig kodon på mRNA, og de aktiverende enzymer som fester den rette aminosyren til dens tRNA. Dette er den slags kompleksitet som gjennomsyrer biologiske systemer, og som utgjør en så formidabel utfordring for en evolusjonær forklaring på opprinnelsen. Det ville være usannsynlig nok hvis koden bare ble implementert av tRNAene som har 70 til 80 nukleotider; men den like avgjørende og komplementære rollen til de aktiverende enzymene, som er hundrevis av aminosyrer lange, utelukker enhver realistisk mulighet for at denne typen ordning kunne ha oppstått opportunistisk.
Bilde: Koding i ribosomet
Progressiv utvikling av den genetiske koden er ikke realistisk
I lys av de mange komponentene som er involvert i implementeringen av den genetiske koden, har forskere om livets opprinnelse prøvd å se hvordan den kan ha oppstått på en gradvis, evolusjonær måte. For eksempel blir det vanligvis foreslått at til å begynne med brukes koden bare på noen få aminosyrer, som deretter gradvis økte i antall. Men denne typen scenario støter på alle slags vanskeligheter med noe så grunnleggende som den genetiske koden.
1. For det første ser det ut til at de tidlige kodonene bare har brukt to baser (som kan kode for opptil 16 aminosyrer); men en påfølgende endring til tre baser (for å imøtekomme 20) ville forstyrre koden alvorlig. Når de anerkjenner denne vanskeligheten, antar de fleste forskere at koden brukte 3-baserte kodoner fra begynnelsen; som var bemerkelsesverdig tilfeldig eller innebærer en viss grad av fremsyn fra evolusjonens side (som selvfølgelig ikke er tillatt).
2. Mye mer alvorlige er implikasjonene for proteiner basert på et sterkt begrenset sett med aminosyrer. Spesielt hvis koden var begrenset til bare noen få aminosyrer, må det antas at tidlige aktiverende enzymer bare omfattet det begrensede settet med aminosyrer, og likevel hadde det nødvendige spesifisitetsnivået for pålitelig implementering av koden. Det er ingen bevis for dette; og påfølgende omorganisering av enzymene når de benyttet seg av nylig tilgjengelige aminosyrer, ville kreve svært usannsynlige endringer i deres konfigurasjon. Lignende begrensninger vil gjelde proteinkomponentene i ribosomene som har en like viktig rolle i translasjon.
3. Videre har tRNAer en tendens til å ha atypiske baser som syntetiseres på vanlig måte, men deretter modifiseres. Disse modifikasjonene blir utført av enzymer, så også disse enzymene trenger å ha startet livet basert på et begrenset antall aminosyrer; eller det må antas at disse modifikasjonene er senere forbedringer - selv om de ser ut til å være nødvendige for pålitelig implementering av koden.
4. Til slutt, hva skal motivere tilsetningen av nye aminosyrer til den genetiske koden? De ville ha lite om noe bruk før de ble innlemmet i proteiner - men det vil ikke skje før de er inkludert i den genetiske koden. Så de nye aminosyrene må syntetiseres og på en eller annen måte innlemmes i nyttige proteiner (av enzymer som mangler dem), og alt nødvendig maskineri for å inkludere dem i koden (dedikerte tRNAer og aktiverende enzymer) blir satt på plass - og alt gjort til egen fordel (opportunistisk)! Helt usannsynlig! -lenke.
Sammenligning av oversettelsesbelastninger for standard og alternative genetiske koder
 Opprinnelsen og universaliteten til den genetiske koden er en av de største gåtene i biologien. Rett etter at den genetiske koden til Escherichia coli ble dekryptert, ble det innsett at denne spesifikke koden, av mer enn 1084 mulige koder, deles av alle studerte livsformer (om enn noen ganger med mindre modifikasjoner). Spørsmålet om hvordan denne spesifikke koden dukket opp og hvilke fysiske eller kjemiske begrensninger og evolusjonskrefter som har formet dens svært ikke-tilfeldige kodonoppgave, er gjenstand for en intens debatt. Spesielt antas funksjonen at kodoner som skiller seg fra et enkelt nukleotid, vanligvis for den samme eller en kjemisk veldig lik aminosyre og den tilhørende blokkstrukturen til tilordningene, antas å være en nødvendig betingelse for robustheten til den genetiske koden både mot mutasjoner, samt mot feil i oversettelsen -lenke.
Opprinnelsen og universaliteten til den genetiske koden er en av de største gåtene i biologien. Rett etter at den genetiske koden til Escherichia coli ble dekryptert, ble det innsett at denne spesifikke koden, av mer enn 1084 mulige koder, deles av alle studerte livsformer (om enn noen ganger med mindre modifikasjoner). Spørsmålet om hvordan denne spesifikke koden dukket opp og hvilke fysiske eller kjemiske begrensninger og evolusjonskrefter som har formet dens svært ikke-tilfeldige kodonoppgave, er gjenstand for en intens debatt. Spesielt antas funksjonen at kodoner som skiller seg fra et enkelt nukleotid, vanligvis for den samme eller en kjemisk veldig lik aminosyre og den tilhørende blokkstrukturen til tilordningene, antas å være en nødvendig betingelse for robustheten til den genetiske koden både mot mutasjoner, samt mot feil i oversettelsen -lenke.
Hadde Wright rett? Den kanoniske genetiske koden er et empirisk eksempel på en adaptiv topp i naturen; Avvikende genetiske koder utviklet seg ved hjelp av adaptive broer -lenke.
Feilminimeringshypotesen postulerer at den kanoniske genetiske koden utviklet seg som et resultat av seleksjon for å minimere de fenotypiske effektene av punktmutasjoner og oversettelsesfeil.
Grassos kommentar: Hvordan kan forfatterne hevde at det allerede var oversettelse, hvis det avhenger av at den genetiske koden allerede er satt opp /
Det er sannsynlig at koden i sin tidlige evolusjon hadde få eller til og med et minimalt antall tRNAer som dekodet flere kodoner gjennom wobble-kobling, med flere aminosyrer og tRNAer som ble lagt til etter hvert som koden utviklet seg.
Grassos kommentar: Hvorfor hevder forfatterne at den genetiske koden dukket opp basert på evolusjonært selektivt trykk, hvis det ikke var noen evolusjon i det hele tatt? Evolusjon starter med DNA-replikering, som avhenger av at oversettelse allerede er fullstendig satt opp. Opprinnelsen til tRNA er også et stort problem for tilhengere av abiogenese, fordi de er svært spesifikke, og deres biosyntese i moderne celler er en svært kompleks, flerstegsprosess som krever mange komplekse enzymer.
...
Mangelen på grunnlag i mekanismen som bygger på de fysisk-kjemiske teoriene for opprinnelsen til den genetiske koden motsatt den troverdige og naturlige mekanismen som ble foreslått av Q2-koevolusjons teorien 1. april 2016
 Flertallet av teoriene avanserte for å forklare opprinnelsen til Q4, den genetiske koden hevder at de fysisk-kjemiske egenskapene til aminosyrer hadde en grunnleggende rolle for å organisere strukturen til den genetiske koden ....... men dette ser ikke ut til å ha vært tilfelle. De fysisk-kjemiske egenskapene til aminosyrer spilte bare en underordnet rolle i å organisere koden - og viktig bare hvis den forstås som manifestasjon av katalysen utført av proteiner. Mekanismen som ligger på flertallet av teoriene basert på de fysisk-kjemiske egenskapene til aminosyrer, er ikke troverdige eller i det minste ikke tilfredsstillende -her.
Flertallet av teoriene avanserte for å forklare opprinnelsen til Q4, den genetiske koden hevder at de fysisk-kjemiske egenskapene til aminosyrer hadde en grunnleggende rolle for å organisere strukturen til den genetiske koden ....... men dette ser ikke ut til å ha vært tilfelle. De fysisk-kjemiske egenskapene til aminosyrer spilte bare en underordnet rolle i å organisere koden - og viktig bare hvis den forstås som manifestasjon av katalysen utført av proteiner. Mekanismen som ligger på flertallet av teoriene basert på de fysisk-kjemiske egenskapene til aminosyrer, er ikke troverdige eller i det minste ikke tilfredsstillende -her.
Det er nok data til å tilbakevise muligheten for at den genetiske koden ble tilfeldig konstruert ('en frossen ulykke'). For eksempel grupperer den genetiske koden visse aminosyretilordninger. Aminosyrer som deler den samme biosyntetiske banen, har en tendens til å ha samme første base i kodonene. Aminosyrer med lignende fysiske egenskaper har en tendens til å ha lignende kodoner. (Se samme farge i bildet til høyre.)
Enten bunn-opp-prosesser (f.eks. ukjente kjemiske prinsipper som gjør koden til en nødvendighet), eller bunn-opp-begrensninger (dvs. en slags seleksjonsprosess som skjedde tidlig i livsutviklingen, og som favoriserte koden vi har nå), da vi kan dispensere fra kodemetaforen. Den ultimate forklaringen på koden har ingenting å gjøre med valg eller handlefrihet; den er til slutt produktet av nødvendighet.
Når vi reagerer på 'kodeskeptikerne', må vi huske på at de er bundet av sin egen metode for å forklare opprinnelsen til den genetiske koden i ikke-teleologiske, kausale termer. De må forklare hvordan ting skjedde på den måten de antar. Hvis en kodeskeptiker skulle hevde at levende ting har koden de har, fordi det er en som nøyaktig og effektivt oversetter informasjon på en måte som tåler støynivået, erstatter han/hun ulovlig en teleologisk forklaring for en effektiv årsakssammenheng. Vi må spørre skeptikeren: Hvordan kom naturen til en så ideell kode som den vi finner i levende ting i dag? -lenke.
Genetisk kode: Heldig sjanse eller grunnleggende naturlov?
Det blir klart at informasjonskoden er iboende knyttet til de fysiske lovene i universet, slik at livet kan være et uunngåelig resultat av vårt univers. Mangelen på suksess med å forklare kodenes opprinnelse og selve livet de siste tiårene, tyder på at vi savner noe veldig grunnleggende om livet, muligens noe grunnleggende om materie og selve universet. Visselig var innføringen av den genetiske koden ikke noe 'sjansespill'.
Relevant om materie -lenke.
Oversettelse og bilder ved Asbjørn E. Lund